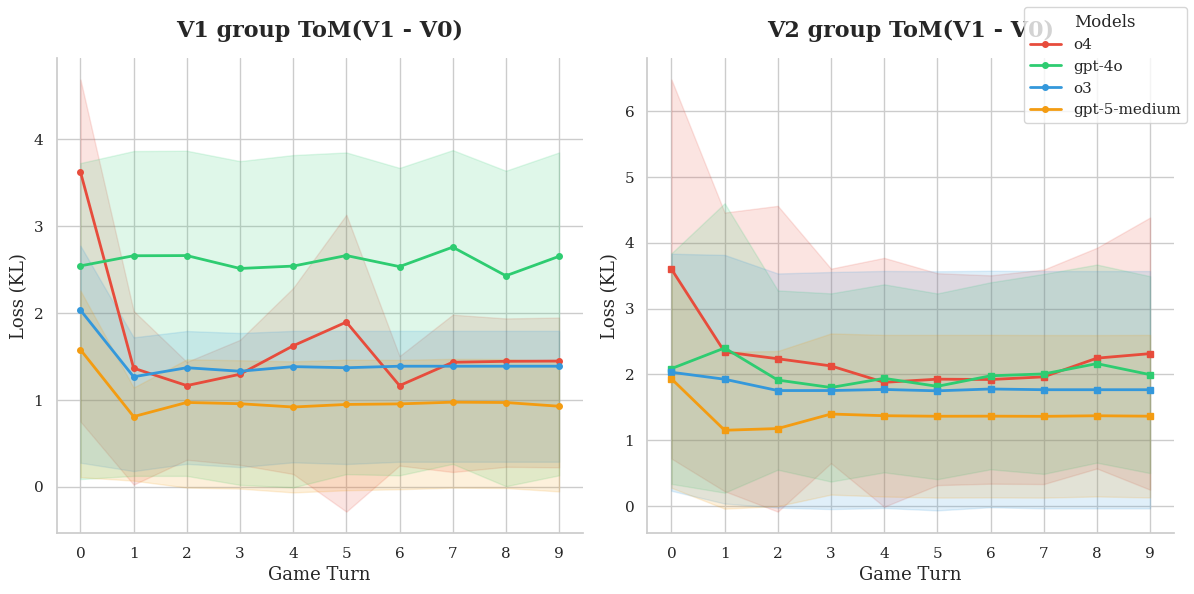
Experimental Setup
The protocol follows Section 4 of the paper and keeps the decision policy unconstrained by explicit strategy instructions.
- Models: GPT-4o, o3, o4-mini, GPT-5 (medium reasoning effort).
- Evaluation regime: self-play (same-model vs same-model).
- Task set: first half of predefined instances (20 out of 40).
- Opponent baseline: same-model agent outputting only
V0. - Compared groups:
V0-group,V1-group,V2-group. - No policy instruction is added for how ToM reports should be used; usage is implicit.
Why this matters: the setup isolates whether richer ToM traces change behavior/calibration without hand-coding a reasoning policy.